
IT安全運維| 數(shù)據(jù)防泄露DLP簡介
2020-05-10 18:45 作者:艾銻無限 瀏覽量:
在企業(yè)IT運維中提到數(shù)據(jù)保護,大家可能常常想起文檔,很少有人會關(guān)注文檔中的內(nèi)容,對數(shù)據(jù)的管理也比較單一,通常就是全加密、全授權(quán),對文檔的重要性不做區(qū)分,隨著社會的發(fā)展,文檔的格式越來越多,安全事件的不斷爆發(fā),使得人們對數(shù)據(jù)的關(guān)注度發(fā)生了變化,數(shù)據(jù)也分成了結(jié)構(gòu)化數(shù)據(jù)和非結(jié)構(gòu)化數(shù)據(jù),更加的關(guān)注文檔內(nèi)容中的敏感信息,使用文檔的應(yīng)用有哪些,對不同類型的文檔、含有不同內(nèi)容的文檔有區(qū)別的管理和存儲。以前要管控數(shù)據(jù),大多是強管控,直接全部隔離,或者全部加密,我們稱之為囚籠、枷鎖式的管控,在實際的數(shù)據(jù)生產(chǎn)、使用、流轉(zhuǎn)中帶來了很多不必要的麻煩,人們需要更加靈活的方式來處理數(shù)據(jù),此時,智能化的數(shù)據(jù)安全管控應(yīng)運而生,企業(yè)IT運維可以按照數(shù)據(jù)的重要程度有針對性的對數(shù)據(jù)進行控制。數(shù)據(jù)防泄漏的核心能力
什么是DLP呢?字面上翻譯為“Data Leakage(Loss) Prevention數(shù)據(jù)泄露防護”,其核心能力就是內(nèi)容識別,通過識別可以擴展到對數(shù)據(jù)的防控。內(nèi)容識別應(yīng)該具備的識別能力具體來說有關(guān)鍵字、正則表達式、文檔指紋、確切數(shù)據(jù)源(數(shù)據(jù)庫指紋)、支持向量機,針對于每一種能力又會衍伸出多種復(fù)合能力。DLP還應(yīng)該具備防護能力,防護范圍包括網(wǎng)絡(luò)防護和終端防護。網(wǎng)絡(luò)防護主要以審計、控制為主,終端防護除審計與控制能力外,還應(yīng)包含傳統(tǒng)的主機控制能力、加密和權(quán)限控制能力。總的來說,DLP其實就是一個綜合體,最終實現(xiàn)的效果,應(yīng)該是智能發(fā)現(xiàn)、智能加密、智能管控、智能審計,也是一整套的數(shù)據(jù)泄露防護方案。
數(shù)據(jù)防泄漏的組件構(gòu)成
下圖說明DLP的實體配置,以及不同模型在組織內(nèi)的常駐位置。“網(wǎng)絡(luò) DLP”產(chǎn)品常駐于 DMZ 中,而其他產(chǎn)品則常駐于企業(yè) LAN 或數(shù)據(jù)中心。 除了“終端 DLP”產(chǎn)品以外,所有其他產(chǎn)品都是以服務(wù)器為基礎(chǔ)。
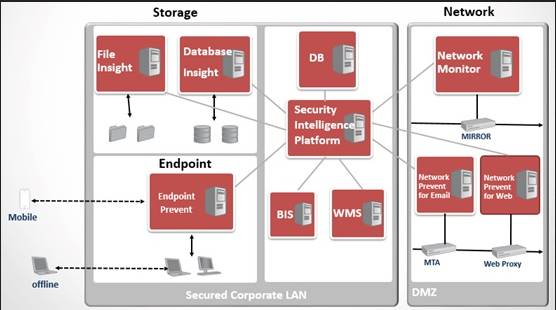
為了預(yù)防數(shù)據(jù)丟失,無論數(shù)據(jù)的存儲、復(fù)制或傳輸位置在哪里,都必須準(zhǔn)確地檢測所有類型的機密數(shù)據(jù)。如果沒有準(zhǔn)確的檢測,數(shù)據(jù)安全系統(tǒng)就會生成許多誤報 (將并未違規(guī)的消息或文件標(biāo)識為違規(guī)) 以及漏報 (未將違反策略的消息或文件標(biāo)識為違規(guī))。誤報會大量耗費進行進一步調(diào)查和解決明顯事故所需的時間和資源。漏報會掩蓋安全漏洞,導(dǎo)致數(shù)據(jù)丟失、潛在財務(wù)損失、法律風(fēng)險并有損組織聲譽。因此需要準(zhǔn)確的檢測技術(shù)來做保障。為了確保最高的準(zhǔn)確性,DLP 采用了三種基礎(chǔ)檢測技術(shù)和三種高級檢測技術(shù)。
1、基礎(chǔ)檢測技術(shù)
基礎(chǔ)檢測技術(shù)中通常有三種方式,正則表達式檢測(標(biāo)示符)、關(guān)鍵字和關(guān)鍵字對檢測、文檔屬性檢測。基礎(chǔ)檢測方法采用常規(guī)的檢測技術(shù)進行內(nèi)容搜索和匹配,比較常見的都是正則表達式和關(guān)鍵字,此兩種方法可以對明確的敏感信息內(nèi)容進行檢測;文檔屬性檢測主要是針對文檔的類型、文檔的大小、文檔的名稱進行檢測,其中文檔的類型的檢測是基于文件格式進行檢測,不是簡單的基于后綴名檢測,對于修改后綴名的場景,文件類型檢測可以準(zhǔn)確的檢測出被檢測文件的類型,目前支持100多種標(biāo)準(zhǔn)的文件類型,并且可以通過自定義特征,去識別特殊的文件類型格式的文檔。
2、高級檢測技術(shù)
高級檢測技術(shù)中也有三種方式,精確數(shù)據(jù)比對 (EDM)、指紋文檔比對 (IDM)、向量分類比對 (SVM)。EDM 用于保護通常為結(jié)構(gòu)化格式的數(shù)據(jù),例如客戶或員工數(shù)據(jù)庫記錄。IDM和SVM 用于保護非結(jié)構(gòu)化的數(shù)據(jù),例如 Microsoft Word 或 PowerPoint 文檔。對于 EDM、IDM、SVM 而言,敏感數(shù)據(jù)會先由企業(yè)標(biāo)識出來,然后再由DLP判別其特征,以進行精準(zhǔn)的持續(xù)檢測。判別特征的流程包括DLP訪問和檢索文本及數(shù)據(jù)、予以正規(guī)化,并使用不可逆的打亂方式進行保護。
DLP 檢測是以實際的機密內(nèi)容為基礎(chǔ),而非根據(jù)文件本身。因此,DLP不只能檢測敏感數(shù)據(jù)的檢索項或衍生項,而且能夠標(biāo)識文件格式與特征信息格式不同的敏感數(shù)據(jù)。例如,如果已經(jīng)判別出機密 Microsoft Word 文檔的特征,DLP就能夠在相同的內(nèi)容以 PDF 附件的方式通過電子郵件進行提交時,將其準(zhǔn)確檢測出來。
(1)精確數(shù)據(jù)比對
精確數(shù)據(jù)比對 (EDM) 可保護客戶與員工的數(shù)據(jù),以及其他通常存儲在數(shù)據(jù)庫中的結(jié)構(gòu)化數(shù)據(jù)。例如,客戶可能會撰寫有關(guān)使用 EDM 檢測的策略,以在消息中查找“名字”、“身份證號”、“銀行帳號”或“電話號碼”其中任意三項同時出現(xiàn)的情況,并將其映射至客戶數(shù)據(jù)庫中的記錄。EDM 允許根據(jù)特定數(shù)據(jù)列中的任何數(shù)據(jù)欄組合進行檢測;也就是在特定記錄中檢測 M 個字段中的 N 個字段。它能夠在“值組”或指定的數(shù)據(jù)類型集上觸發(fā);例如,可接受名字與身份證號這兩個字段的組合,但不接受名字與手機號這兩個字段的組合。由于會針對每個數(shù)據(jù)存儲格存儲一個單獨的打亂號碼,因此只有來自單個列的映射數(shù)據(jù)才能觸發(fā)正在查找不同數(shù)據(jù)組合的檢測策略。例如,有個EDM 策略請求“名字+ 身份證號+手機號”的組合,則“張三”+“13333333333”“110001198107011533” 可觸發(fā)此策略,但是即使 “李四”也位于同一數(shù)據(jù)庫中,“李四”+“13333333333”“110001198107011533”也不能觸發(fā)此策略。EDM 也支持相近邏輯以減少可能的誤報情形。對于檢測期間所處理的自由格式文本而言,單個特征列中所有數(shù)據(jù)各自的字?jǐn)?shù)均必須在可配置的范圍內(nèi),方可視為匹配項。例如,依默認,在檢測到的電子郵件正文的文本中,“張三”+“13333333333”“110001198107011533”各自的字?jǐn)?shù)必須在選定的范圍內(nèi),才會出現(xiàn)匹配項。對于含有表式數(shù)據(jù) (例如 Excel 電子表格) 的文本而言,單個特征列中所有數(shù)據(jù)都必須位于表式文本的同一行上,方可視為匹配項,以減少整體誤報情形。
(2)指紋文檔比對
“指紋文檔比對”(IDM) 可確保準(zhǔn)確檢測以文檔形式存儲的非結(jié)構(gòu)化數(shù)據(jù),例如 Microsoft Word 與 PowerPoint 文件、PDF 文檔、財務(wù)、并購文檔,以及其他敏感或?qū)S行畔ⅰDM 會創(chuàng)建文檔指紋特征,以檢測原始文檔的已檢索部分、草稿或不同版本的受保護文檔。IDM 首先要進行敏感文件的學(xué)習(xí)和訓(xùn)練,拿到敏感內(nèi)容的文檔時, IDM采用語義分析的技術(shù)進行分詞,然后進行語義分析,提出來需要學(xué)習(xí)和訓(xùn)練的敏感信息文檔的指紋模型,然后利用同樣的方法對被測的文檔或內(nèi)容進行指紋抓取,將得到的指紋與訓(xùn)練的指紋進行比對,根據(jù)預(yù)設(shè)的相似度去確認被檢測文檔是否為敏感信息文檔。這種方法可讓 IDM 具備極高的準(zhǔn)確率與較大的擴展性。
(3)向量機分類比對
支持向量機(Support Vector Machines)是由Vapnik等人于1995年提出來的。之后隨著統(tǒng)計理論的發(fā)展,支持向量機也逐漸受到了各領(lǐng)域研究者的關(guān)注,在很短的時間就得到很廣泛的應(yīng)用。支持向量機是建立在統(tǒng)計學(xué)習(xí)理論的VC維理論和結(jié)構(gòu)風(fēng)險最小化原理基礎(chǔ)上的,利用有限的樣本所提供的信息對模型的復(fù)雜性和學(xué)習(xí)能力兩者進行了尋求最佳的折中,以獲得最好的泛化能力。SVM的基本思想是把訓(xùn)練數(shù)據(jù)非線性的映射到一個更高維的特征空間(Hilbert空間)中,在這個高維的特征空間中尋找到一個超平面使得正例和反例兩者間的隔離邊緣被最大化。SVM的出現(xiàn)有效的解決了傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)結(jié)果選擇問題、局部極小值、過擬合等問題。并且在小樣本、非線性、數(shù)據(jù)高維等機器學(xué)習(xí)問題中表現(xiàn)出很多令人注目的性質(zhì),被廣泛地應(yīng)用在模式識別,數(shù)據(jù)挖掘等領(lǐng)域。SVM比對算法適合那些具有微妙的特征或很難描述的數(shù)據(jù),如財務(wù)報告和源代碼等。使用過程中,先將文檔按照內(nèi)容細分化分類,每一類文檔集合有屬于本類的意義,經(jīng)過SVM比對,確定被檢測的文檔屬于哪一類,并取得此類文檔的權(quán)限和策略。 同時,針對SVM的特點,可以進行終端或服務(wù)器上的文檔按照分類含義進行分類數(shù)據(jù)發(fā)現(xiàn)。IDM和SVM的比對區(qū)別是,IDM將待檢測文件的指紋和訓(xùn)練模型中的每一個文件進行指紋比對;而SVM是將待檢測文件向量化,并歸屬到某一類訓(xùn)練集所建立的向量空間。
艾銻無限科技專業(yè):IT外包、企業(yè)外包、北京IT外包、桌面運維、弱電工程、網(wǎng)站開發(fā)、wifi覆蓋方案,網(wǎng)絡(luò)外包,網(wǎng)絡(luò)管理服務(wù),網(wǎng)管外包,綜合布線,服務(wù)器運維服務(wù),中小企業(yè)it外包服務(wù),服務(wù)器維保公司,硬件運維,網(wǎng)站運維服務(wù)
以上文章由北京艾銻無限科技發(fā)展有限公司整理
相關(guān)文章
- [網(wǎng)絡(luò)服務(wù)]保護無線網(wǎng)絡(luò)安全的十大
- [網(wǎng)絡(luò)服務(wù)]無線覆蓋 | 無線天線對信
- [網(wǎng)絡(luò)服務(wù)]綜合布線 | 綜合布線發(fā)展
- [數(shù)據(jù)恢復(fù)服務(wù)]電腦運維技術(shù)文章:win1
- [服務(wù)器服務(wù)]串口服務(wù)器工作模式-服務(wù)
- [服務(wù)器服務(wù)]串口服務(wù)器的作用-服務(wù)維
- [服務(wù)器服務(wù)]moxa串口服務(wù)器通訊設(shè)置參
- [網(wǎng)絡(luò)服務(wù)]網(wǎng)絡(luò)運維|如何臨時關(guān)閉
- [網(wǎng)絡(luò)服務(wù)]網(wǎng)絡(luò)運維|如何重置IE瀏覽
- [網(wǎng)絡(luò)服務(wù)]網(wǎng)絡(luò)運維|win10系統(tǒng)升級后
- [辦公設(shè)備服務(wù)]辦公設(shè)備:VPN簡介
- [辦公設(shè)備服務(wù)]辦公設(shè)備:VPN技術(shù)的要求



 關(guān)閉
關(guān)閉